
Das schafft einen interessanten Ausgangspunkt: Denn zwischen der privaten Nutzung – geprägt von persönlichem Orientierungsbedarf und einer direkten User Experience – und dem professionellen Einsatz im Versorgungsalltag liegen nicht nur unterschiedliche Anforderungen, sondern auch sehr unterschiedliche Vorstellungen davon, was KI leisten soll und darf.
Entwicklung und Spannungsfeld
Die Interpretation medizinischer Daten erfolgt im Gesundheitswesen auf mehreren Ebenen – von der Messung einzelner Laborwerte bis zur komplexen Therapieentscheidung. Mit der rasanten Entwicklung großer Sprachmodelle (LLMs) wie ChatGPT Health und Claude for Healthcare entstehen neue Werkzeuge, die eine hochgradig aggregierte Interpretation ermöglichen. Das schafft ein Spannungsfeld: Einerseits bieten LLMs eine ganzheitliche Sicht auf verstreute Gesundheitsdaten und liefern Nutzer:innen direkt verwertbare Einordnungen. Andererseits stehen sie im Vergleich zur traditionellen, spezialisierten Interpretation durch medizinische Fachkräfte – insbesondere dort, wo kontextabhängige, regelbasierte und fachlich tiefe Befundung nötig ist.
Dieser Beitrag beleuchtet die Ebenen der Dateninterpretation, die reale Nutzung von LLMs im Gesundheitswesen (trotz verständlicher Vorbehalte) und warum eine differenzierte, mehrstufige Interpretation – gerade in der Labormedizin – weiterhin unverzichtbar bleibt.
Wie wir Nutzung verstehen: Befragung versus reales Verhalten
Die Diskussion um LLMs in der Medizin wird oft von berechtigten Vorbehalten begleitet: Datenschutz, Verantwortlichkeiten, fehlende Transparenz, potenzielle Halluzinationen und die Frage, ob sensible Informationen in Online-Systeme gehören.
Gleichzeitig zeigt sich in der Praxis eine dynamische Realität: Viele nutzen GPT & Co. bereits – teils offiziell in Pilotkontexten, teils informell als „zweites Paar Augen“ für Formulierungen, Zusammenfassungen oder Einordnungen.
Methodisch lässt sich das in zwei Perspektiven fassen:
- Befragungen: Was geben Ärzt:innen, wie sie KI nutzen (oder nutzen würden)?
- Reales Verhalten: Was wird tatsächlich genutzt, in welchen Situationen und mit welchen Mustern?
Gerade diese zweite Perspektive ist oft aufschlussreich, weil sie zeigt, wo der klinische Alltag heute bereits pragmatisch Entscheidungen trifft – unabhängig davon, ob die Debatte vollständig geklärt ist.
LLMs im Gesundheitswesen: neue Werkzeuge, neue Nutzungskontexte
Große Sprachmodelle haben in kurzer Zeit Einzug in den Gesundheitsbereich gehalten. Dabei lassen sich zwei unterschiedliche Stoßrichtungen beobachten:
- Endnutzer:innen-orientierte Anwendungen (z. B. ChatGPT Health)
Diese Systeme sind darauf ausgelegt, Menschen beim Verstehen ihrer Gesundheitsinformationen zu unterstützen: Erklärungen zu Befunden, Vorbereitung auf Arztgespräche, Zusammenfassungen und Trendbetrachtungen. Der Fokus liegt häufig auf Verständlichkeit, Orientierung und der Verbindung verschiedener persönlicher Datenquellen. - Professionelle bzw. B2B-orientierte Anwendungen (z. B. Claude for Healthcare)
Hier steht die Einbettung in Prozesse von Leistungserbringern und Kostenträgern im Vordergrund: Dokumentationsunterstützung, administrative Workflows, strukturierte Aufbereitung von Informationen, sowie die datenschutzkonforme Integration in bestehende Systeme.
Wichtig ist: Beide Richtungen verschieben Interpretation nach „oben“ – weg von einzelnen Datenpunkten hin zu aggregierten, fallbezogenen Zusammenfassungen. Das ist sinnvoll, birgt aber auch Risiken, wenn Spezifität, Referenzlogik, lokale Standards und diagnostische Pfade nicht sauber berücksichtigt werden.
Der Datenstack: Von der Generierung bis zur Therapieentscheidung
Um zu verstehen, auf welcher Ebene interpretierende Systeme wirken, hilft ein Blick auf den „Datenstack“ im Gesundheitswesen: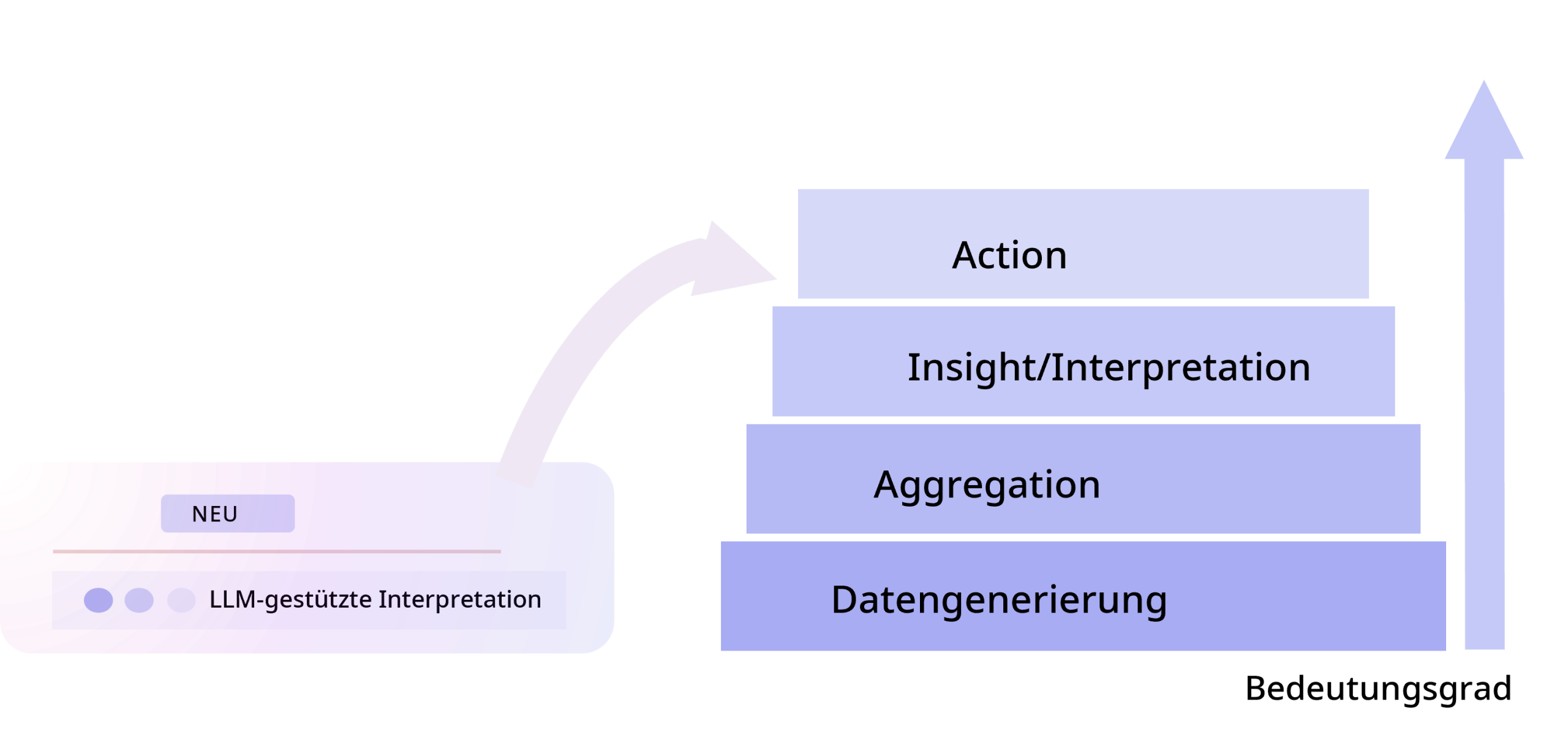
Grundsätzlich gilt: Je weiter oben im Stack interpretiert wird, desto mehr Informationen stehen potenziell zur Verfügung – etwa wenn neben Laborwerten auch Radiologie, Klinikverlauf und Medikation einfließen. Gleichzeitig steigt die Gefahr, dass spezifische diagnostische Logik „verallgemeinert“ wird und lokale Details untergehen.
Das Labor als Ort klinischer Interpretation
Laboratorien werden oft als Datenlieferanten gesehen – faktisch sind sie jedoch auch Orte hochspezialisierter Interpretation. Labormedizin bedeutet nicht nur Messung, sondern auch:
- technische Validierung (Analytik, Plausibilität, Präanalytik)
- kontextualisierte Einordnung (Referenzintervalle, Interferenzen, Muster)
- Kommunikation und Beratung entlang klinischer Fragestellungen
- strukturierte Befundkommentare und Hinweise zur Einordnung
Gerade in komplexen Fragestellungen ist „Interpretation im Labor“ ein wichtiger Bestandteil der diagnostischen Qualität.
Reflex und „Insight to Action“: warum Workflows entscheidend sind
Ein zentraler Mehrwert entsteht nicht allein durch „bessere Texte“, sondern durch intelligente Workflows, die Interpretation in Handlung übersetzen – und zwar regelbasiert, nachvollziehbar und reproduzierbar.
Das Prinzip lässt sich so beschreiben:
- Insight: Erkennen, was der Befund in diesem Kontext bedeutet (inkl. Unsicherheiten und Alternativen).
- Action: ableiten, was sinnvollerweise als nächster Schritt erfolgen sollte (z. B. Zusatzparameter, Verlaufskontrolle, Differenzierungstest).
Gerade in der Labormedizin ist dieses „Insight to Action“ seit Jahren etabliert – etwa über definierte Diagnostikpfade und Reflexstrategien. LLMs können hier ergänzen, indem sie Informationen verständlich bündeln oder klinische Kontexte strukturieren. Der entscheidende Unterschied bleibt jedoch: Workflows müssen lokal korrekt sein (Referenzen, SOPs, Indikationslogik, Verantwortlichkeiten) und dürfen nicht durch generische, global gemittelte Antworten ersetzt werden.

